VFX Creator: Animated Visual Effect Generation with Controllable Diffusion Transformer

VFX Creator is an efficient framework based on a Video Diffusion Transformer, enabling spatial and temporal control for visual effect (VFX) video generation. With minimal training data, a plug-and-play mask control module allows precise instance-level manipulation, while the integration of tokenized start-end motion timestamps with text space provides fine-grained temporal control over the VFX rhythm.
Results of VFX Creator
Abstract
Crafting magic and illusions stands as one of the most thrilling facets of filmmaking, with visual effects (VFX) serving as the powerhouse behind unforgettable cinematic experiences. While recent advances in generative artificial intelligence have catalyzed progress in generic image and video synthesis, the domain of controllable VFX generation remains comparatively underexplored. More importantly, fine-grained spatial-temporal controllability in VFX generation is critical, but challenging due to data scarcity, complex dynamics, and precision in spatial manipulation. In this work, we propose a novel paradigm for animated VFX generation as image animation, where dynamic effects are generated from user-friendly textual descriptions and static reference images. Our work makes two primary contributions: i) Open-VFX, the first high-quality VFX video dataset spanning 15 diverse effect categories, annotated with textual descriptions, instance segmentation masks for spatial conditioning, and start–end timestamps for temporal control; This dataset features a wide range of subjects for the reference images, including characters, animals, products, and scenes. ii) VFX Creator, a simple yet effective controllable VFX generation framework based on a Video Diffusion Transformer. The model incorporates a spatial and temporal controllable LoRA adapter, requiring minimal training videos. Specifically, a plug-and-play mask control module enables instance-level spatial manipulation, while tokenized start-end motion timestamps embedded in the diffusion process accompanied by the text encoder, allowing precise temporal control over effect timing and pace.
Open-VFX Dataset

Overview of our proposed Open-VFX Dataset. (a) demonstrates diverse input inference images in the dataset, including humans, animals, objects, and various scenes across single and multiple components. (b) shows the text descriptions of the proposed 15 VFXs, and (c) presents an example (Explode it) VFX.
Videos Examples of Open-VFX Dataset
| Cake-ify it | Crumble it | Crush it | Decapitate it | Deflate it |
|---|---|---|---|---|
| Dissolve it | Explode it | Eye-pop it | Inflate it | Levitate it |
| Melt it | Squish it | Ta-da it | Transform into Harley Quinn, mastering allure and chaos | Transform into a black Venom |
Method of VFX Creator
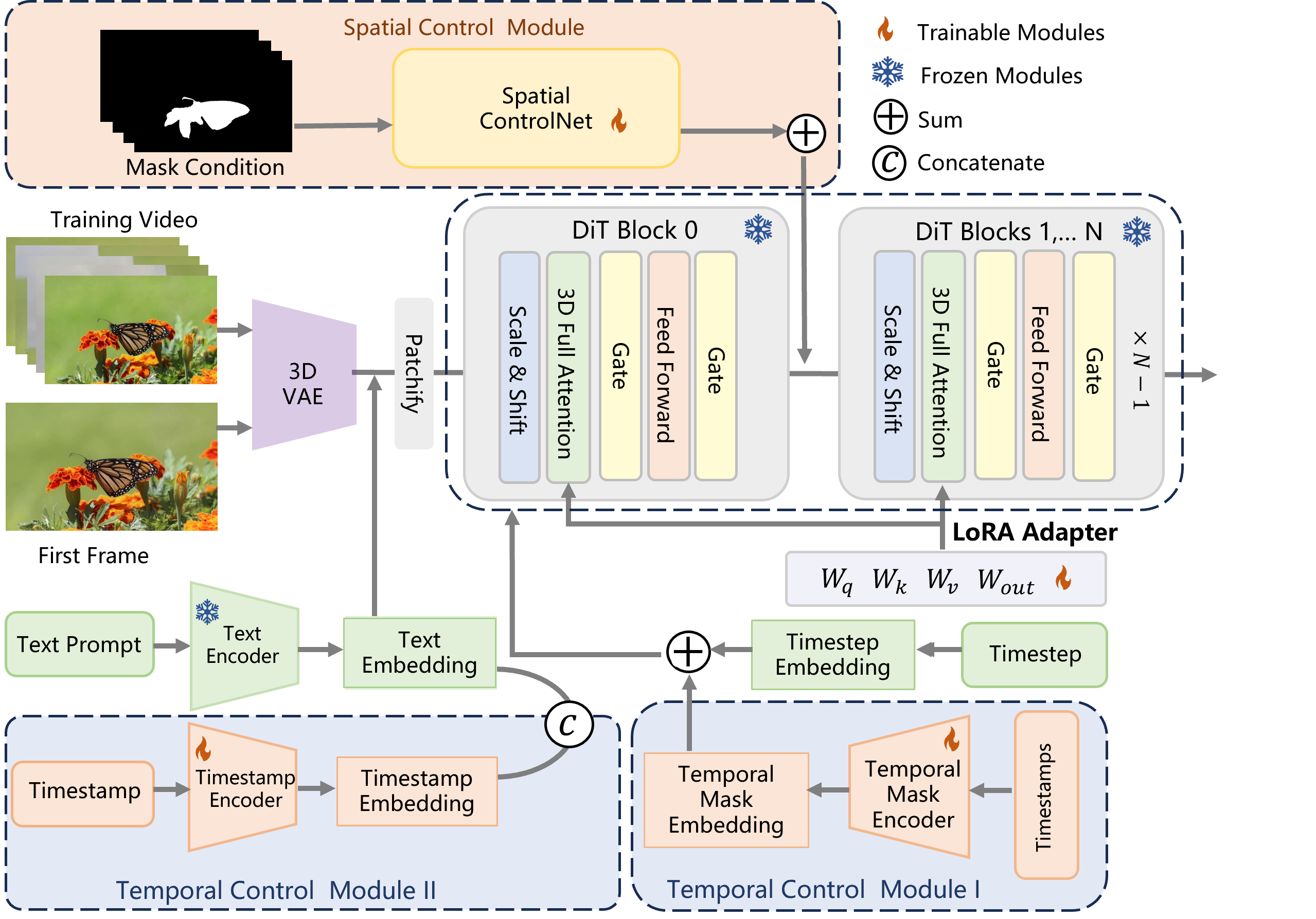
We introduce two novel modules: (a) Spatial Controlled LoRA Adapter. This module integrates a mask-conditioned ControlNet with LoRA, injecting mask sequences into the model to enable instance-level spatial manipulation. (b) Temporal Controlled LoRA Adapter. We explore two strategies for incorporating temporal control: module I involves tokenizing start-end motion timestamps and embedding them into the diffusion process alongside the text space, while module II integrates temporal mask with timestep embeddings to guide the diffusion process.
Comparisons Results
| CogVideoX | LTX-Video | Pika | Ours |
|---|---|---|---|
Crumble it.
|
Crumble it.
|
Crumble it.
|
Crumble it.
|
Deflate it.
|
Deflate it.
|
Deflate it.
|
Deflate it.
|
Dissolve it.
|
Dissolve it.
|
Dissolve it.
|
Dissolve it.
|
Ta-da it.
|
Ta-da it.
|
Ta-da it.
|
Ta-da it.
|
Eye-pop it.
|
Eye-pop it.
|
Eye-pop it.
|
Eye-pop it.
|
Inflate it.
|
Inflate it.
|
Inflate it.
|
Inflate it.
|
Spatial Control
| Levitate it | |||
|---|---|---|---|
 |
 |
||
 |
 |
||
 |
 |
||
| Ta-da it | |||
 |
 |
||
 |
 |
||
 |
|
||
Temporal Control
| Start: 1fr (0s); End: 32fr (4s). |
Start: 4fr (0.5s) End: 32fr (4s). |
Start: 12fr (1.5s); End: 32fr (4s). |
|---|---|---|
| Start: 8fr (1s); End: 24fr (3s). |
Start: 8fr (1s); End: 40fr (5s). |
Start: 16fr (2s); End: 32fr (4s). |
| Start: 16fr (2s); End: 40fr (5s). |
Start: 16fr (2s); End: 40fr (5s). |
Start: 20fr (2.5s); End: 40fr (5s). |
| Start: 24fr (3s); End: 48fr (6s). |
Start: 30fr (3.75s); End: 48fr (6s). |
Start: 32fr (4s); End: 48fr (6s). |